Facteurs de viralité sur Linkedin
Le projet consiste à comprendre l’origine de la viralité sur Linkedin au travers d’une approche sémantique appliquée à un jeu de données constitué de plus de 4 millions de posts. L’exploitation du corpus a été rendu possible grâce au cabinet d’études de marché IntoTheMinds.
Plusieurs analyses statistiques ont déjà été réalisées qui ont révélées l’influence de 3 facteurs spécifiques, notamment la place des émojis et de la longueur du post.
Les prochaines étapes du projet consiste à réaliser une analyse sémantique fine des posts les plus viraux afin d’identifier les facteurs qui sont susceptibles d’expliquer l’engagement des internautes sur ces contenus.
Effets des émojis
Un travail important a été effectué sur l’effet statistique des signes dans les publications Linkedin. Pour ce faire :
- un algorithme d’extraction des signes à partir des messages
- une analyse été réalisée pour en sortir les statistiques d’utilisation des émojis par pays
- une analyse par équation structurelles a été réalisée pour comprendre l’effet statistique des émojis sur la viralité des messages.
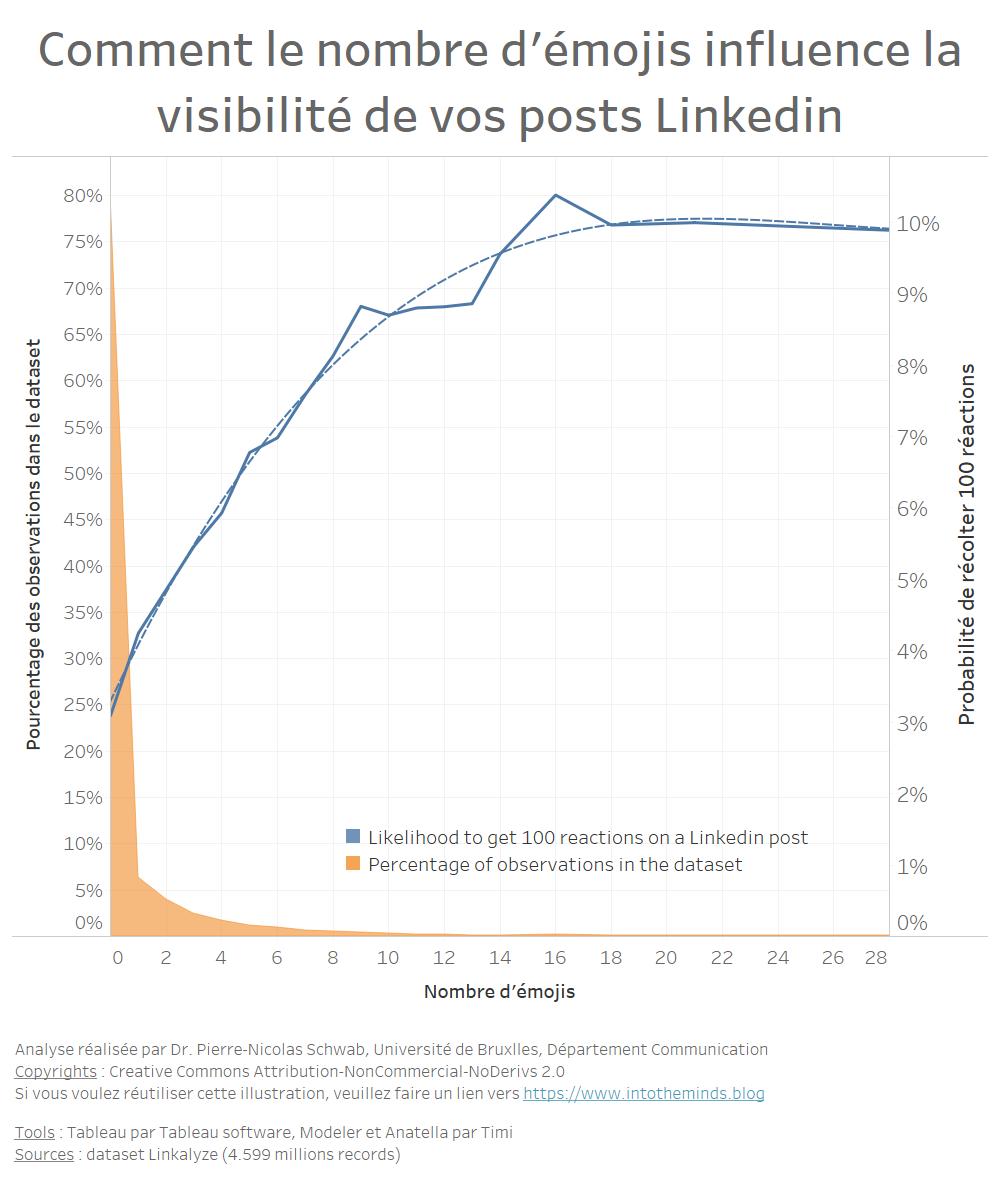
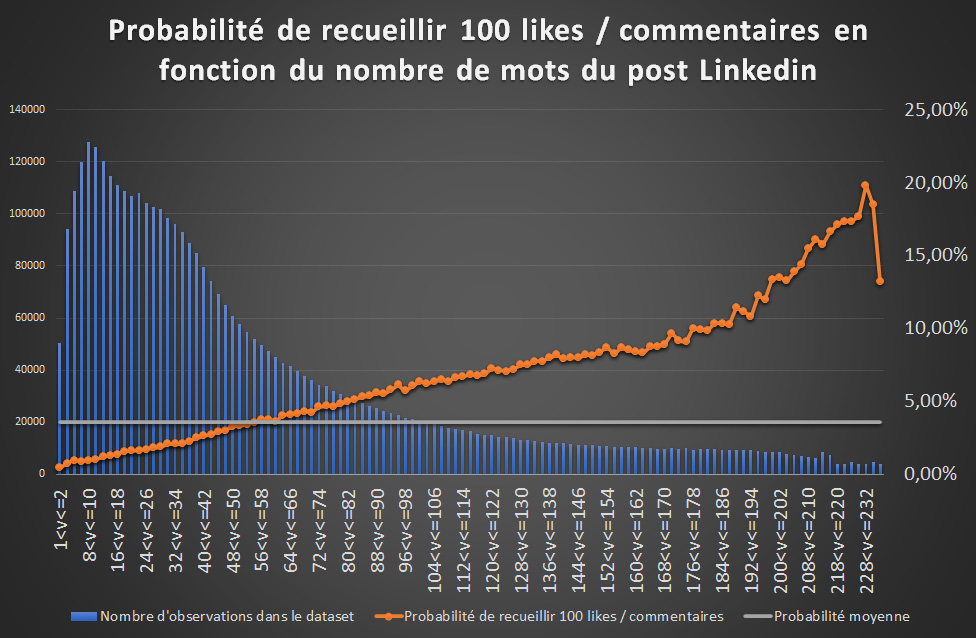
Étude par équations structurelles des cause de viralité
Pour finir, une étude par équations structurelles a été réalisée pour comprendre le rôle des caractères extrinsèques d’un post Linkedin sur sa viralité. Une vingtaine de variables ont été étudiées :
- Longueur du texte (nombre de mots)
- Nombre d’émojis
- Taille du réseau
- Hashtags
- Langue
- …
L’analyse a été réalisée avec Timi Modeller. Ci-dessous les corrélations en fonction du nombre de mots.
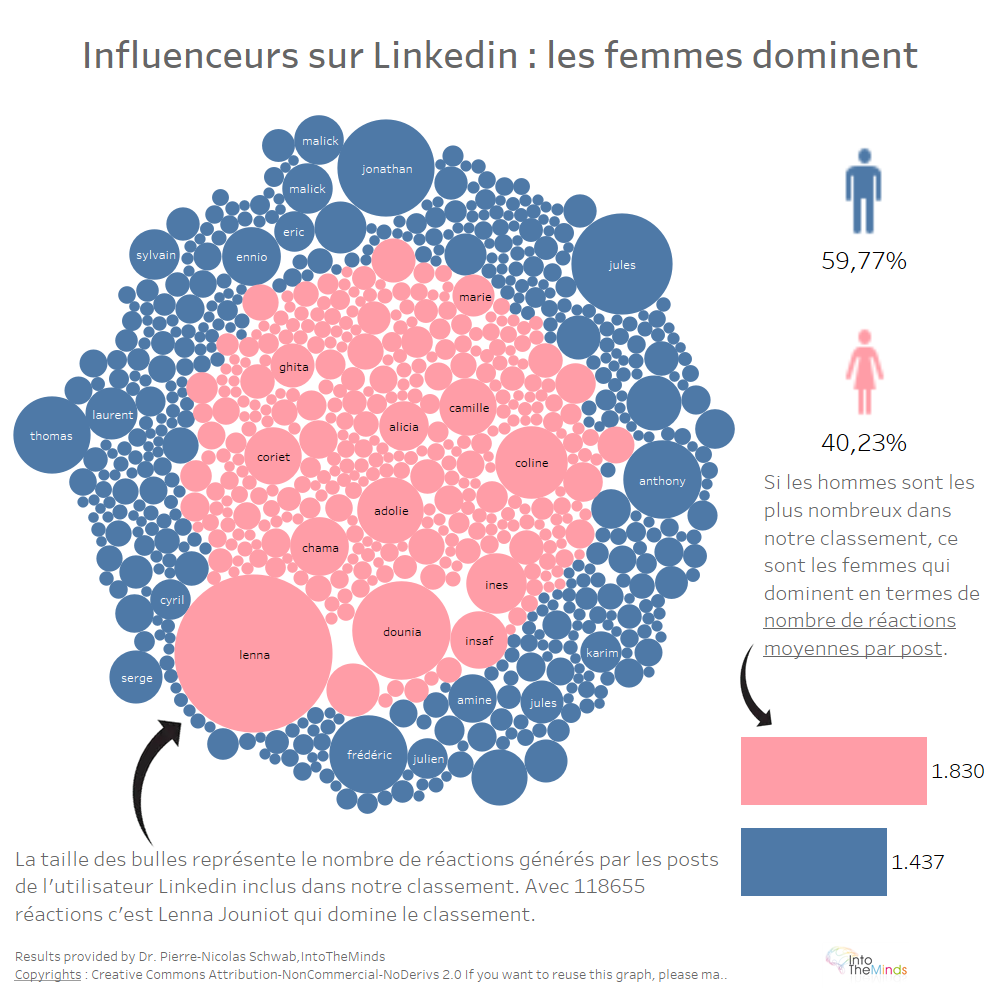
Impact du genre
Un travail de fond a été réalisé sur la qualification des données extraites. En particulier :
- Isolement des messages les plus populaires (= viraux)
- Réconciliation de ces messages avec l’identité de leur auteur.rice
- Enrichissement des données des profil avec l’âge et le sexe sur la base d’un corpus de prénoms constitué ad hoc
- Analyse statistique des messages en fonction de l’âge et du genre
Les recherches au corpus des messages en anglais et ai annoté à la main plus de 5000 messages (contre à peu près 1000 en français). Ce gros travail de fond va permettre de tester la reproductibilité des conclusions dans une autre langue.
Axes de travail pour 2023
En 2023 plusieurs axes de travail sont prévus :
- vérifier la validité des résultats en administrant une enquête quantitative sur panel via un institut de sondage
- Analyse qualitative des messages viraux (sémantique, humour, sujet) et classification
- extraction d’éléments caractéristiques des messages comme par exemples les chiffres, les émojis
- Analyse du corpus en anglais et comparaison avec les résultats en français